Read A3.final file after running GIZA++
in Blog
As instructed in this post, the only file we need after running GIZA++ is A3.final. How to read it right, and is there a faster way to do it? This is the purpose of today’s post.
A few note about result file (A3.final):
- Accuracy of alignment based on how large your corpus, the good in preprocessing (Tokenization, stemmed, normalize…).
- After tunning, the language chosen as source will have these connections: 1-1, 1-n, 1-0. On the opposite, the target language only have 1-1 connection. That is the reason you should switch place of source-target and rerun to have the best result.
- Source target will have 1 more word-token named “NULL”, which is the world will be aligned with words in Target which have no corresponding mate with Source language. You can look at picture below for easy understanding of this concept.
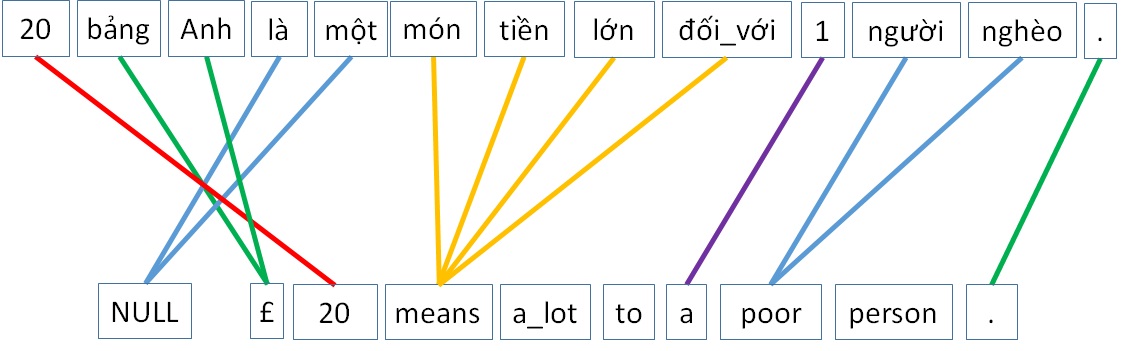 Aligned result after running GIZA++ on billigual corpus Vietnamese-English with English is the source and Vietnamese is target language.
Aligned result after running GIZA++ on billigual corpus Vietnamese-English with English is the source and Vietnamese is target language.
How to read it?
The easiest way is running below example code in Python with following input and output:
- Input: 3 sample lines in result file
# Sentence pair (7) source length 10 target length 14 alignment score : 2.08562e-23
+ 20 bảng Anh là một món tiền lớn đối_với một người nghèo .
NULL ({ 5 6 }) + ({ 1 }) £ ({ 3 4 }) 20 ({ 2 }) means ({ 7 8 9 10 }) a_lot ({ }) to ({ }) a ({ 11 }) poor ({ 12 13 }) person ({ }) . ({ 14 })
- Output: Aligned result. Those words in “()” are words in Target which are aligned with immediately preceeding word in Source.
NULL (là,một) £ (bảng,Anh) 20 (20) means (món,tiền,lớn,đối_với) a_lot () to () a (một) poor (người,nghèo) person () . (.)
Code:
line_1 = "20 bảng Anh là một món tiền lớn đối_với một người nghèo ."
line_2 = "NULL ({ 4 5 }) £ ({ 2 3 }) 20 ({ 1 }) means ({ 6 7 8 9 }) a_lot ({ }) to ({ }) a ({ 10 }) poor ({ 11 12 }) person ({ }) . ({ 13 })"
token_list_1 = line_1.split()
token_list_2 = line_2.split()
aligned = ''
flag = True
correspond_token_list = []
for token in token_list_2:
if True == flag:
if '({' == token:
flag = False
aligned += '('
correspond_token_list = []
else:
aligned += token + ' '
else:
if '})' == token:
flag = True
aligned += ','.join(correspond_token_list) + ') '
else:
correspond_token_list.append(token_list_1[int(token)-1])
print (aligned)
Reference:
- http://www.statmt.org/moses/?n=FactoredTraining.RunGIZA